友情链接:

Google DeepMind 近日发表了一篇论文,详备先容了其生成式视频模子 Veo 3 所展现出的“零样本”学习与推理材干,并提议了一个与大型说话模子中的“想维链”相对应的中枢见识——“帧链”(CoF,Chain-of-Frames)。探求团队通过对逾越 18,000 个生成视频的分析,系统地展示了 Veo 3 在未经过任何特定任务微调的情况下,管束从基础感知到复杂视觉推理等一系列问题的后劲。这篇题为《视频模子是零样本学习者和推理者》(Video models are zero-shot learners and reasoners)的论文,明确提议了一个论点:正如 LLM(Large Language Model,大型说话模子)长入了天然说话处理范畴,生成式视频模子正走在成为机器视觉范畴通用基础模子的说念路上。
 图丨相干论文(泉源:arXiv)
]article_adlist-->
图丨相干论文(泉源:arXiv)
]article_adlist-->在往常几年中,天然说话处理(NLP,Natural Language Processing)范畴经验了一场首要的变革,从为翻译、纲领、问答等每个任务构建成心的“定制模子”,转向了由一个长入的、可通过辅导(prompting)管束种种化问题的 LLM 主导的时间。如今的机器视觉范畴,在某种进度上正在复现 NLP 变革前的气象:咱们领有在特定任务上进展超卓的模子,举例用于物体检测的 YOLO 系列或用于图像分割的 Segment Anything,但忙碌一个仅通过指示就能管束绽开式视觉问题的通用模子。DeepMind 的探求东说念主员觉得,促使 LLM 材干浮现的中枢身分——即在汇集范畴的数据集上旁观大型生成模子——雷同适用于现代的视频模子。Veo 3 的实验成果,恰是为了考证这一判断。
此项探求的亮点在于,它鉴戒了大型说话模子中广为东说念主知的“想维链”(CoT,Chain-of-Thought),并创造性地提议了一个视觉范畴的平行见识——“帧链”(CoF,Chain-of-Frames)。想维链通过将复杂问题领会为一系列中间推理圭表,并以文本花样安闲生成,极地面增强了说话模子的逻辑推理材干。
DeepMind 指出,视频生成在内容上是一个逐帧期骗变化的经过,这种时空上的序列生成,赶巧为视觉问题提供了一种内在的、次序渐进的管束有谋略,这等于“帧链”。说话模子操纵的是东说念主类发明的记号,而视频模子则径直在时刻和空间这两个物理维度上期骗改变。因此,帧链推理使得视频模子有后劲通过一步步生成画面,来管束需要多步权谋和动态领悟的复杂视觉任务。
为系统地评估 Veo 3 的材干,探求团队构建了一个涵盖四个层级的材干框架:感知(Perception)、建模(Modeling)、操控(Manipulation)和推理(Reasoning)。在最基础的感知层面,Veo 3 展示了在莫得经过显式旁观的情况下,完成一系列经典狡计机视觉任务的材干,包括图像分割、角落检测、关节点定位、超鉴别率、盲去蒙胧和去噪。这些“浮现”出的材干,意味着视频模子将来可能取代现在很多需要成心旁观的视觉器具模子。
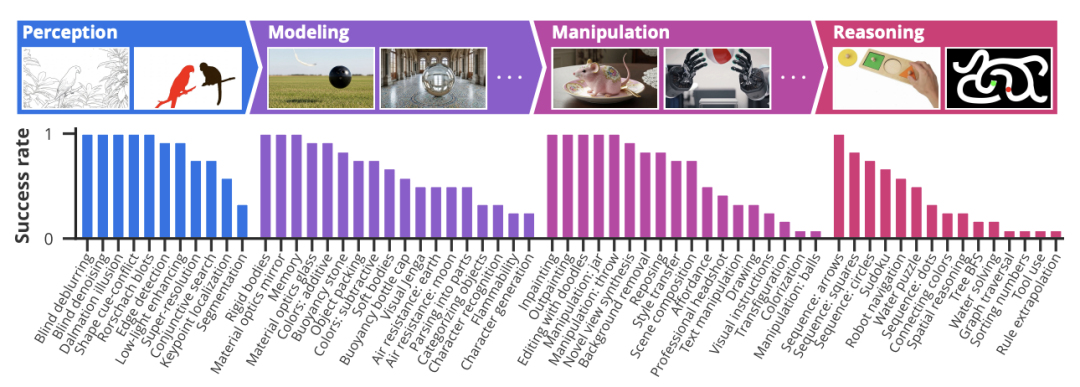 图丨Veo 3 零样本材干的定性概览(泉源:arXiv)
图丨Veo 3 零样本材干的定性概览(泉源:arXiv)在感知之上是建模材干,即领悟寰宇运转的基本规定,尤其是直观物理。Veo 3 大概对刚体和柔体的动态、名义交互进行建模,并进展出对浮力、空气阻力、折射与反射等物理景象的领悟。在一个模拟“视觉叠叠乐”(Visual Jenga)的任务中,模子大概以物理上合理的方式移除场景中的物体。它还能领悟物体功能,举例判断哪些物品不错被放进背包。此外,模子还能在时刻和镜头移动中保捏对寰宇气象的挂念,这组成了其进行更复杂操作的基础。
在此之上,等于模子的操控材干。Veo 3 大概实践种种的零样本图像剪辑任务,如配景移除、立场迁徙、图像上色和设置。它还能把柄涂鸦指示剪辑图像,将不同物体合成为一个相助的场景,或将一张自拍肖像窜改为专科的商务头像。这种对场景进行合理修改的材干,使其不错遐想复杂的交互,模拟奢睿的物体操控,举例演示若何卷一个墨西哥卷饼,或让机器东说念主手臂像东说念主类一样天然地提起锤子。
这一系列材干的集成,最终赋予了模子进行视觉推理的材干。这恰是“帧链”机制阐发关节作用的范畴。在迷宫求罢职务中,Veo 3 通过逐帧生成红色方块在白色旅途上的移动,最终停在绿色额外,从而完成任务。其在 5x5 网格迷宫上的告成率(pass@10)达到了 78%,远高于其前代模子 Veo 2 的 14%。
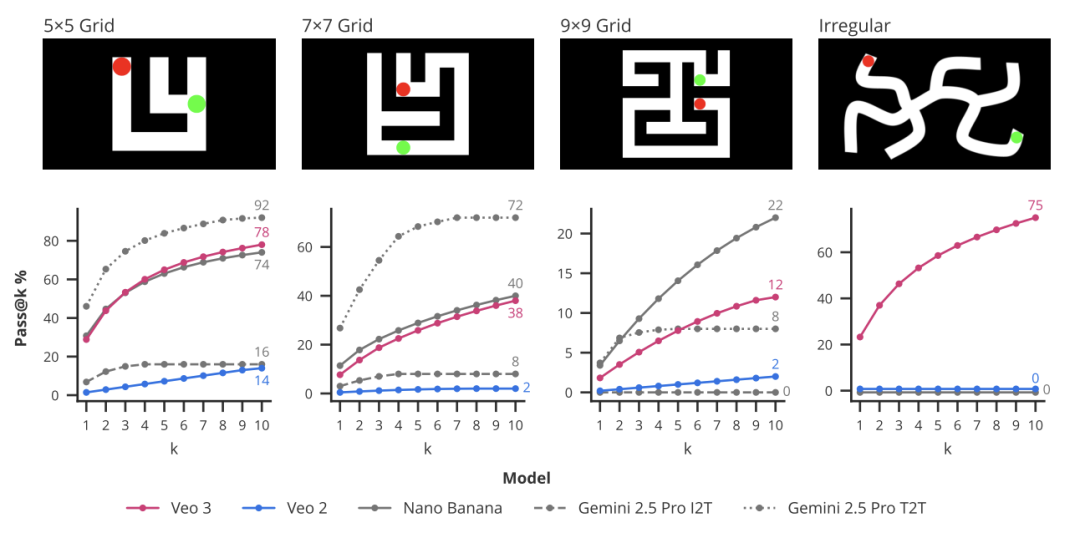 图丨Veo 3 在不同复杂度迷宫中的求解进展(泉源:arXiv)
图丨Veo 3 在不同复杂度迷宫中的求解进展(泉源:arXiv)探求还将其与最近大热的图像模子 Nano Banana 和说话模子 Gemini 2.5 Pro 进行了比拟。成果自满,静态的图像模子难以管束需要经过的迷宫任务,而说话模子天然在处理 ASCII 文本迷宫时进展优异,但在径直领悟图像输入时则濒临费力。这也突显出视频模子通过“帧链”进行安闲视觉推理的独到上风。除了迷宫,Veo 3 还能完成视觉序列补全、说合匹配表情、管束粗浅的数独谜题和视觉对称性补全等任务。
不外,团队示意,现在 Veo 3 在很多任务上的进展仍不足起初进的专用模子,这与 LLM 发展的早期阶段(如 GPT-3 与精调模子的对比)相等雷同。
此外,生成视频的狡计老本已经额外腾贵。但论文征引历史数据指出,LLM 的推理老本正以每年 9 到 900 倍的速率下跌,早期被觉得“部署老本过高”的通用模子,最终凭借其通用性和老本的快速下跌取代了大王人专用模子。要是 NLP 的发展轨迹可行为参考,雷同的趋势也将在视觉范畴献技。
参考贵府:
1. https://arxiv.org/pdf/2509.20328
运营/排版:何晨龙



01/“AI科学家”登顶Nature:MIT团队开导多模态AI平台,全程无东说念骨干扰90天即发现高效电催化剂
02/联发科,用天玑9500界说了个东说念主算力的将来标的
03/华理团队连结打造晶圆级光刻胶千里积期间,精确扫尾薄膜厚度至纳米级,告成通过下一代光刻考证
04/Hinton与LeCun“同台复旧”:英国AI初创打造材料界搜索引擎,称能将材料发现提速十倍
05/科学家管束X射线内窥成像难题,研制1600像素光纤阵列探伤器,可穿透东说念主体及时不雅察肿瘤

 海量资讯、精确解读,尽在新浪财经APP
海量资讯、精确解读,尽在新浪财经APP